10 min to read
Google Introduces Gemini And Updates Bard With Gemini Pro. Why does it matter?

Gemini
Gemini has turned out to be a significant development in the AI sector providing a tough competition to OpenAI’s ChatGPT 4.0 Turbo. Gemini is able to effortlessly work on a number of inputs ranging from text, images, video, audio, and code and it hopes to fulfill tasks with its high-end multimodal capabilities, This versatility marks a significant advancement in AI's ability to enhance our daily experiences. As far as we know, Gemini has already outperformed human experts in Massive Multitask Language Understanding (MMLU). Just for reference, this is a widely recognized benchmark for evaluating AI's knowledge and problem-solving skills. This achievement is seen with enthusiasm among developers as the Gemini's superior performance across various benchmarks, including text and coding, opens new options for solving a number of challenges with the help of automation and model training.
Gemini has been trained to work exceptionally in multimodal benchmarks as well. In domains like image understanding, video captioning, and automatic speech translation, we can see that Gemini demonstrates exceptional capabilities.
As per Google, these benchmarks include complex tasks such as :
- MMMU (Multi-discipline college-level reasoning problems),
- VQAv2 (Natural image understanding), and
- CoVoST 2 (Automatic speech translation in 21 languages),
Gemini is available in three distinct sizes: Ultra, Pro, and Nano.
Ultra- most capable and largest model for highly-complex tasks.
Pro- model for scaling across a wide range of tasks.
Nano- efficient model for on-device tasks.
As we can see, each of these sizes are designed to cater to specific needs, from complex, high-level tasks to efficient, on-device applications. And the best part is that its natively multimodal nature offers unparalleled versatility, transforming any input into a diverse range of outputs. This ability is exemplified in Gemini's capacity to generate code from varied inputs, demonstrating a profound understanding and application of user intent.
Gemini Pro has been integrated into Bard and now is one of the most exciting times to see how it could be used in the future, be it in terms of creativity, planning, and brainstorming.
Trends in capabilities
This report by Google is assessing the performance of their Gemini model family, a group of AI models, across different capabilities. They evaluated these models on over 50 benchmarks, divided into six key areas: Factuality, Long-Context, Math/Science, Summarization, Reasoning, and Multilinguality.
- Factuality: This involves tasks like retrieving information (open or closed book) and answering questions.
- Long-Context: This includes tasks that require understanding and summarizing long texts, as well as answering questions based on them.
- Math/Science: Tasks here involve solving mathematical problems, proving theorems, and answering questions from scientific exams.
- Reasoning: This covers tasks that require arithmetic, scientific, and commonsense reasoning.
- Multilingual: This includes translation, summarization, and reasoning tasks in multiple languages.
- Summarization: It refers to the model's ability to condense long pieces of text into shorter, coherent summaries. This is crucial for scenarios where extracting key information from large volumes of data or text is necessary.
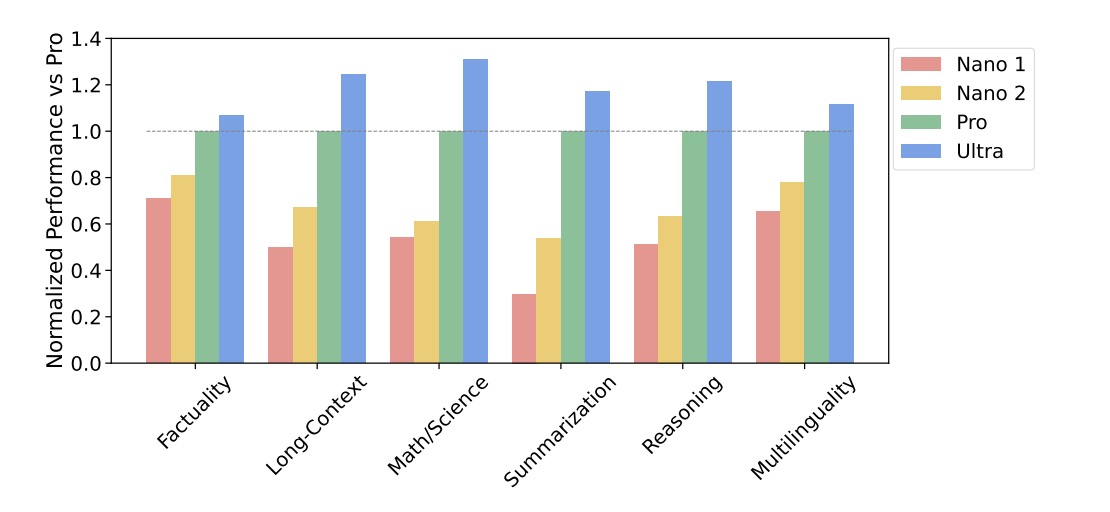
We can also look at this graph by Google which shows us that the larger the model, the better its performance, with Gemini Ultra being the top performer in all six areas. Gemini Pro, the second largest, also shows competitive results but is more efficient to use.
What does it mean in terms of applications?
When considering AI tools for tasks like content creation, data analysis, or customer service, larger, more advanced models like Gemini Ultra can offer superior performance, but it's also important to balance this with considerations of efficiency and resource allocation.
Gemini pro looks promising for coding
Gemini Pro’s technical report shows that it significantly enhances coding efficiency and quality. It understands and generates code in popular languages like Python, Java, C++, and Go, making it very promising for various programming tasks. Its performance is especially notable in coding benchmarks such as HumanEval, an industry-standard for measuring coding task performance, and Natural2Code, an internal dataset focused on author-generated sources, not just web information.
Moreover, Gemini Pro powers advanced coding systems. For instance, it's the engine behind AlphaCode, an AI system that achieved competitive performance in programming contests. Building on this, AlphaCode 2, using a specialized version of Gemini, tackles complex programming problems, integrating math and theoretical computer science.
Gemini Pro excels in both general and competitive programming, making it a valuable tool for coders looking to enhance their productivity and tackle a wide range of coding challenges.
Gemini understands the intent for personalized user experience
While we were researching to see Gemini's multimodal reasoning capabilities, specifically how it understands and responds to a user's intent to create personalized user experiences. Here's a detailed breakdown of how Gemini operates in this context:
Understanding User Intent: Gemini starts by understanding the user's request. For example, taking an example of a very basic activity, the user expresses interest in planning a birthday party for his daughter with an animal theme and an outdoor setting. Gemini recognizes this as a complex request requiring a visually rich and interactive interface, rather than just a text response.
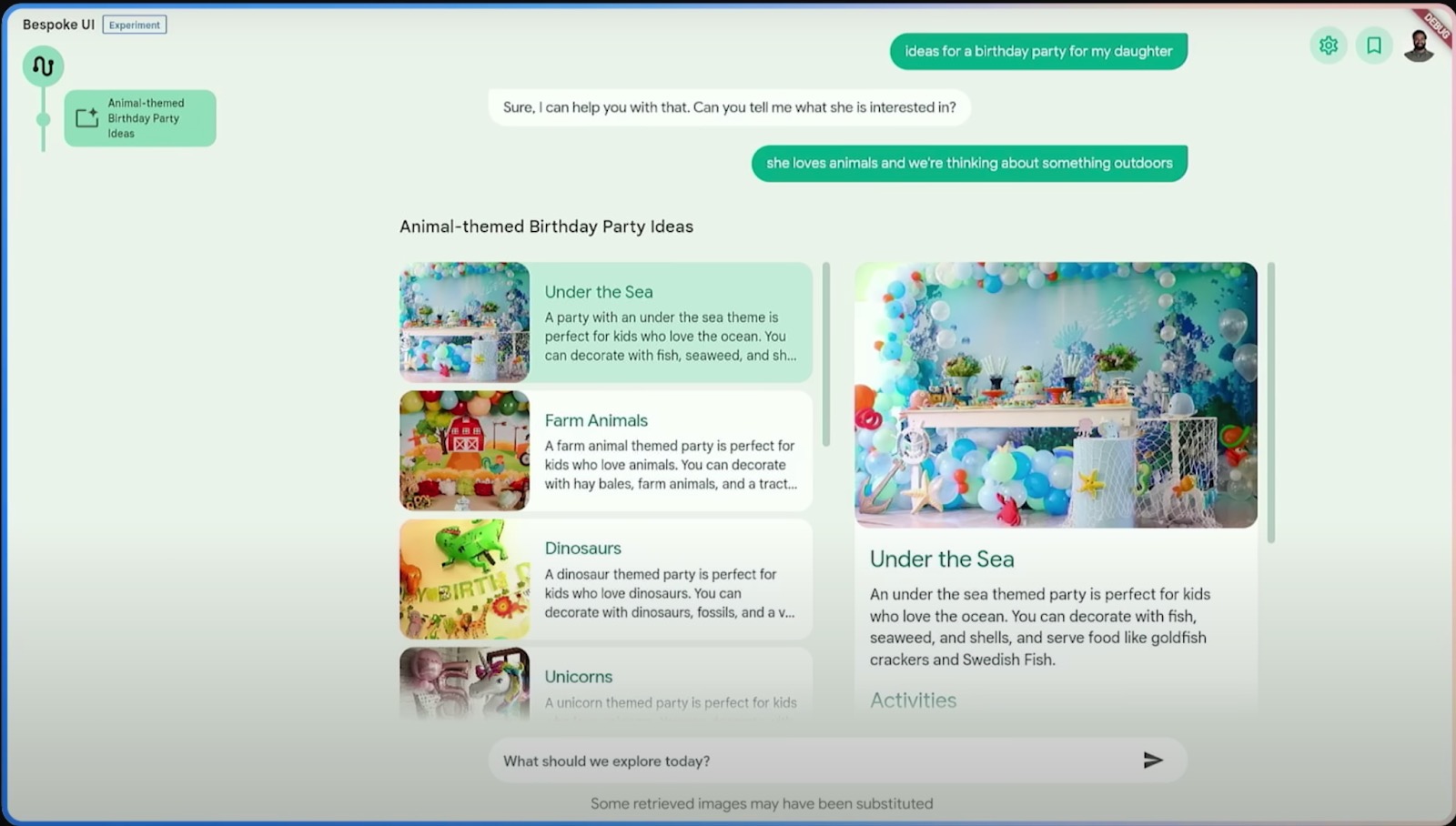
Reasoning and Clarification: Gemini uses reasoning to identify ambiguities in the user's request. For instance, it realizes that specific details about the daughter's animal preference and the type of outdoor party are missing. To address this, it asks clarifying questions to gather more information.
Creating a Product Requirement Document (PRD): Gemini then drafts a PRD outlining the functionality of the desired user experience. It plans to show various party themes, activities, and food options related to the given theme.
Designing the User Experience: Based on the PRD, Gemini designs an interface that allows the user to explore a list of options and delve into details. It decides on a layout that includes a list and detailed views.
Writing Code and Generating Data: Gemini writes the code for the interface in Flutter, using widgets to create the layout. It also generates and retrieves data to populate the interface with relevant content and images.
Interactive Interface: The interface Gemini creates is interactive, allowing the user to click on options and receive more detailed information. For example, when the user shows interest in farm animals and cupcakes, Gemini generates a new UI tailored to provide step-by-step baking instructions.
Adapting to User Choices: As the user interacts with the interface, Gemini adapts and regenerates data to fit the user's choices. It even creates a gallery of images for cake toppers when the user requests it, complete with options to explore different animal-themed toppers.
In my experience so far, this has been amazing. Gemini showcases an advanced level of AI-driven personalization by understanding user intent, asking clarifying questions, creating a tailored PRD, designing an interactive and adaptive interface, and generating real-time data and code. And, now if we talk about how exactly is it going to help you, then you might want to enhance customer engagement and satisfaction through personalized digital experiences.
Multimodal prompting with Gemini
Multimodal prompting refers to an AI's ability to understand and respond to inputs in various forms – visual, auditory, textual, and possibly others – and integrate these inputs to make more nuanced and contextually appropriate responses.

Here's a deeper analysis into what Gemini could do for you:
Visual Recognition and Interpretation: Gemini demonstrates the ability to interpret visual cues. When presented with a drawing, it not only identifies the object (e.g., a bird, a duck) but also provides detailed observations about its features and even infers its material composition.
Contextual Understanding and Adaptation: Gemini shows an understanding of context and adapts its responses accordingly. When additional elements are added to the visual scene (like a squeaking sound), Gemini recalibrates its interpretation (from a bird to a rubber duck).
Integrating Multiple Input Types: Gemini effectively integrates different types of inputs – visual (a piece of paper with a drawing), auditory (squeaking sound), and textual (questions and comments from the user) – to form a coherent response. This showcases its ability to process and synthesize information from multiple sources.
Interactive and Dynamic Responses: The AI dynamically interacts with the user, engaging in games (like “Guess the Country”), offering explanations (like the pronunciation of Mandarin words), and providing creative ideas (suggesting uses for colored yarn). This interaction demonstrates Gemini's ability to not just process information but also engage in creative and playful dialogues.
Cultural and Linguistic Flexibility: Gemini displays linguistic capability by translating phrases into different languages and explaining nuances like tones in Mandarin. This indicates an understanding of linguistic and cultural nuances, which is crucial for personalized and relevant user interactions.
Problem-Solving and Predictive Analysis: Gemini engages in problem-solving (guessing the location of an object) and predictive analysis (anticipating the outcome of a cat's jump), suggesting an ability to reason and make predictions based on given data.
Adapting Output to User Preferences: Gemini's use of emojis in creating a game idea shows its capability to tailor its output format based on the user's preferences, enhancing user engagement and experience.
Gemini involves an advanced level of interaction where the system can process and integrate multiple forms of input, adapt its responses contextually, engage interactively, and provide creative and culturally aware outputs. For CEOs and CMOs, understanding and leveraging such AI capabilities can significantly enhance customer interaction, product development, and marketing strategies, offering more personalized and engaging user experiences.
FAQS - Frequently Asked Questions
What is Gemini and why is it important in the AI sector?
Gemini represents a groundbreaking development within the AI sector, renowned for its sophisticated integration of multimodal capabilities, which seamlessly amalgamate text, image, and potentially other data formats to generate comprehensive AI responses. This importance is underscored by its ability to interpret and generate complex datasets, making it a pivotal tool for advancing AI research and application across various fields. Its significance is further highlighted by the growing demand for AI systems that can understand and process information in ways that mimic human cognitive functions, thereby enhancing decision-making processes, creative endeavors, and personalized user experiences.
How does Gemini's multimodal capabilities enhance user experiences?
Gemini's multimodal capabilities significantly enhance user experiences by providing more intuitive, rich, and engaging interactions. Through its ability to process and generate content across multiple data types, such as text and images, Gemini can deliver responses that are not only contextually accurate but also highly relevant and customized to the user's immediate needs. This multisensory approach enables a more natural and human-like interaction, facilitating a deeper understanding and engagement with content, which is particularly beneficial in educational, entertainment, and marketing contexts.
What are the different sizes of Gemini, and how do they cater to different needs?
Gemini models are designed in various sizes to cater to a broad spectrum of needs, ranging from smaller, more efficient models optimized for speed and low-resource environments, to larger, more complex versions that prioritize depth of understanding and creative generation capabilities. Smaller models are ideal for applications requiring rapid response times and minimal computational resources, making them suitable for mobile and embedded devices. Conversely, larger Gemini models are better suited for tasks demanding extensive data processing and creative output, such as content creation, advanced research, and complex decision-making processes, offering a versatile solution across different computational and application requirements.
How does Gemini Pro integration into Bard benefit users?
The integration of Gemini Pro into Bard significantly benefits users by enhancing the AI's analytical depth, creative generation capabilities, and understanding of nuanced user intent. This amalgamation results in a more sophisticated conversational agent capable of delivering highly personalized, contextually relevant responses and creative content. Users experience improved interaction quality, with more accurate, insightful, and engaging communication. This integration also enables Bard to handle complex queries more effectively, offering solutions and content that better align with user expectations and needs.
What are the key areas Gemini models are evaluated on?
Gemini models are meticulously evaluated on key areas crucial for their effectiveness and applicability: accuracy in understanding and generating content, the ability to process and integrate multimodal data, efficiency in resource utilization, scalability, and adaptability to diverse contexts and user requirements. Additionally, the evaluation focuses on the models' proficiency in handling cultural and linguistic nuances, ensuring personalized user experiences, and their capacity for creative and analytical thinking. These criteria are essential in developing AI models that are not only technologically advanced but also practical and user-friendly.
How does the size of a Gemini model affect its performance?
The size of a Gemini model has a direct impact on its performance, with larger models typically exhibiting greater depth of understanding, more sophisticated data processing capabilities, and enhanced creative generation. However, this comes at the cost of increased computational resources and slower response times. Conversely, smaller models, while being more resource-efficient and faster, may not achieve the same level of depth or creativity in their outputs. This trade-off necessitates careful consideration of the specific requirements and constraints of each application, ensuring that the chosen model size optimally balances performance with practicality.
In what ways does Gemini Pro improve coding efficiency and quality?
Gemini Pro enhances coding efficiency and quality by leveraging advanced AI algorithms and extensive datasets to understand context, predict potential coding outcomes, and suggest optimizations. Its ability to process and analyze large volumes of code in real-time allows for immediate feedback on errors, style inconsistencies, and potential performance issues, significantly reducing debugging and refactoring times. Moreover, Gemini Pro's predictive capabilities can recommend more efficient coding patterns and best practices, fostering a higher standard of code quality and maintainability across projects.
Can you explain how Gemini understands user intent for personalized experiences?
Gemini's understanding of user intent for personalized experiences is rooted in its advanced natural language processing (NLP) and machine learning algorithms, which analyze user inputs, context, and historical interactions to infer underlying goals and preferences. This deep understanding enables Gemini to tailor its responses and recommendations to align with the user's specific needs, interests, and circumstances. By dynamically adjusting its output based on this inferred intent, Gemini provides highly personalized experiences that enhance user satisfaction and engagement.
What is multimodal prompting, and how does Gemini utilize it?
Multimodal prompting refers to the process of providing an AI system with inputs in multiple formats, such as text, images, or voice, to generate responses or outputs that integrate information from these various modalities. Gemini utilizes this capability to understand and process complex queries that require the synthesis of different types of information, enabling it to generate more comprehensive, accurate, and contextually relevant responses. By leveraging multimodal prompting, Gemini can offer a more nuanced and holistic understanding of user requests, enhancing the overall user experience.
How does Gemini's understanding of cultural and linguistic nuances improve user interaction?
Gemini's nuanced understanding of cultural and linguistic subtleties significantly improves user interaction by ensuring that communications are culturally appropriate, sensitive, and relevant. This understanding allows Gemini to tailor its language, tone, and content to reflect the user's cultural background and linguistic preferences, fostering a more inclusive, engaging, and personalized interaction. By acknowledging and respecting these nuances, Gemini enhances its ability to connect with users on a deeper level, promoting more meaningful and satisfying exchanges.

Add comment ×