16 min to read
Fintech: How to Triumph in the Competitive Credit Space Through Data-Driven Marketing?

In the competitive FinTech credit space, data-driven marketing strategies could help you understand customer needs, preferences, and behaviors. However, one thing that is equally crucial is that all your campaigns and strategies are as good as the data and factors that they take into consideration. Hence it becomes imperative that you employ data analytics to segment customers more precisely based on their spending habits, credit history, income, and other relevant factors. And, thanks to the technology, we have a great opportunity to provide customized and tailored solutions in the real time to meet the specific needs of different customer segments.
Make use of Propensity Models to accurately predict the behavior of the customers
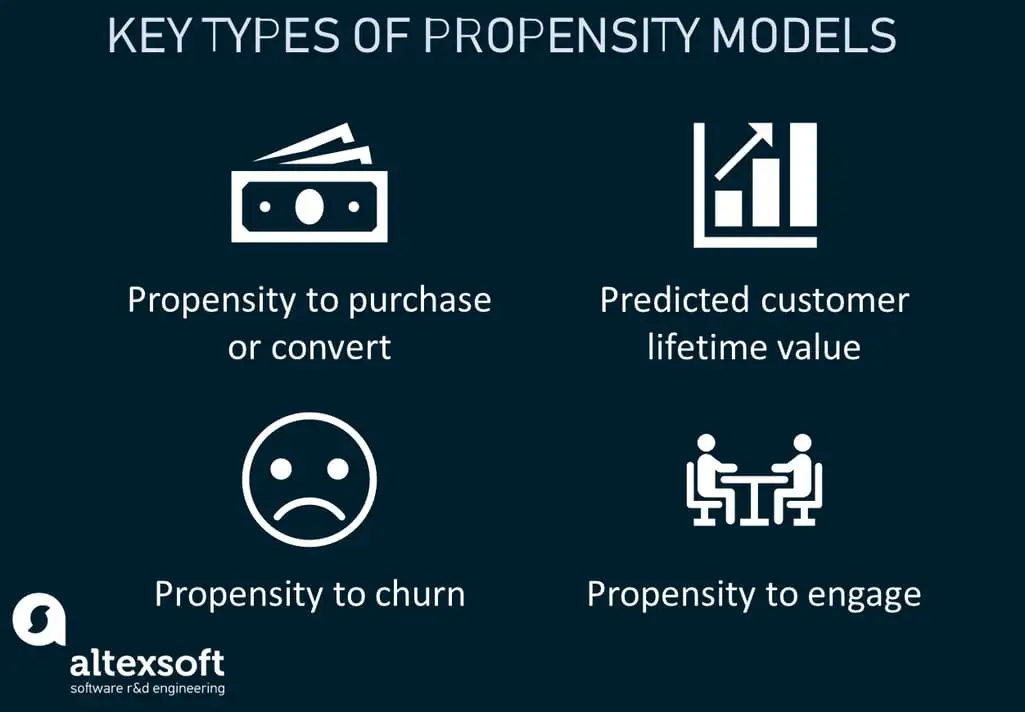
Propensity Models
Credits for image: Altexsoft
If we talk about the basics, then propensity models are simply statistical tools used to predict the likelihood of a customer taking a specific action. This comes in handy with relations to data-driven marketing because we can accurately predict how many conversions, or desired actions will the customer take in a given time frame or for per thousand. In the context of financial services, this could mean predicting how likely a customer is to apply for a loan, respond to a marketing campaign, or choose a particular financial product. When we talk about propensity models, we try to remove any gap for guess work and have a solid understanding of how things will take place leaving us with stronger metrics.
These models analyze historical data and customer behavior to identify patterns and correlations. For example, they could examine past loan applications, account usage, transaction histories, and even external factors like economic trends.
How do we build the right model to ensure higher accuracy?
The first step of data preprocessing is data cleaning. There are high chances that your dataset may contain anomalies which might lead to anomalies in the predicted results. Hence, this first step involves removing errors, inconsistencies, and handling missing values in the dataset.
Step 2 - Normalization: Data is normalized to ensure that all variables are on a similar scale, particularly important when dealing with diverse data types (e.g., income levels vs. number of transactions).
Step 3 - Identifying Relevant Variables: At the same time, it is of equal importance to determine which factors (features) are most predictive of the behavior being modeled. For instance, in predicting loan default risk, features like payment history, income level, and credit score could be crucial. See, you need the right factors to be taken into account when you are working with predictive analysis. There could be one and there could also be more than one feature which basically co-relate with each other to together give a homogeneous overview of the entire dataset. Depending on the fintech startups, their goals, and their exact target market, there are endless possibilities of choosing the right set of variables.
How to build the right model for predictive analysis?
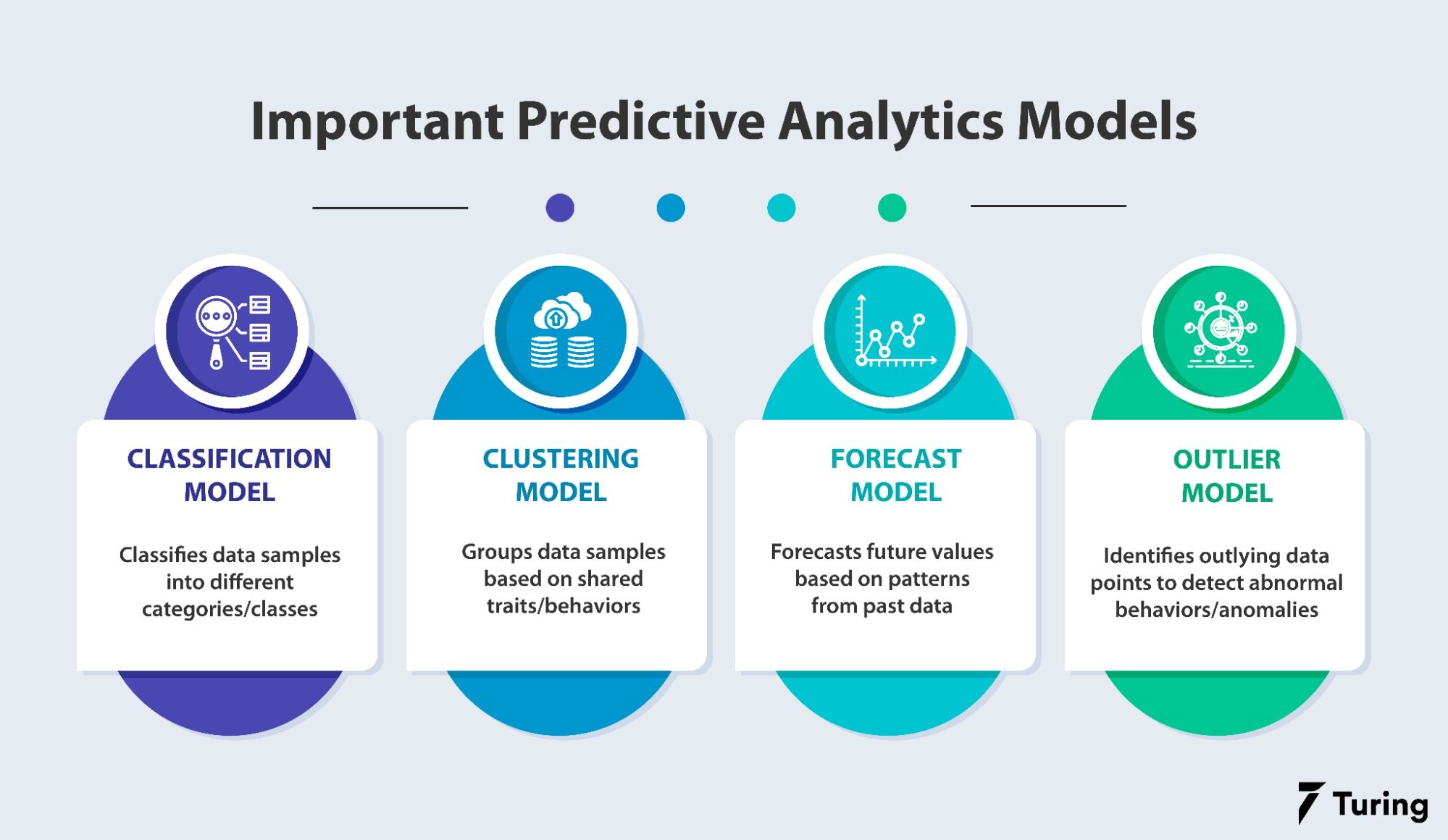
Right model for predictive analysis
Credits for image: Turing
There are various statistical or machine learning models that you can consider including logistic regression, decision trees, or neural networks, but it totally depends on the goal and what outcome you are expecting.
Let me try to explain these models with examples to help you have a better understanding about these technical terms and their implications:
Logistic Regression - Logistic regression is a statistical method used for binary classification problems — where the outcome is binary, like yes/no, true/false, or 0/1.
So, let’s talk about a very basic example where your fintech startup helps a bank to predict whether a customer will default on a loan (Yes or No). Here 0s and 1s can come in handy. The bank could use logistic regression to analyze factors like credit score, income, and loan amount to predict the probability of default. In this situation, the banks will have sufficient data to predict how much they are going to recover from loans and how much money will be defaulted. So, the banks here could have better financial projections.
Decision Trees
Decision trees are flowchart-like structures that split the data into branches to make a prediction. Each branch represents a decision based on a certain variable. If we talk about it in even simpler terms, let’s try to understand that your fintech startup offers various personalized solutions to your customers, and at each step you are trying to extract information and depending on the results, you are customizing your overall offering.
So, at this stage you could use a decision tree that asks a series of questions based on user data: age, income, existing debt, etc. Depending on the answers (branches), the tree leads to a recommendation — like a savings account, a credit card, or an investment plan.
Neural Networks
Neural networks are a set of algorithms, modeled loosely after the human brain, designed to recognize patterns. They interpret sensory data through machine perception, labeling, and clustering of raw input. It is more likely useful for startups that have to analyze and extract from a very large dataset.
For example, there are various new trading platforms that are trying to analyze vast amounts of data, including historical prices, trading volumes, and economic indicators, to identify patterns and make predictions about future market movements.
How do you train your model?
The selected model is trained using historical data. This process involves the model learning the patterns and correlations that exist within the data.
Testing with New Data: The model is tested with a separate set of data (not used in training) to evaluate its accuracy and predictive power. This technique involves repeatedly splitting the data into training and test sets to ensure the model's reliability and reduce the chance of overfitting.
In our current situation of winning in the competitive credit space, these propensity models could:
- Analyze past loan application data to identify characteristics of customers who applied for similar loans.
- Examine transaction histories to understand spending habits that correlate with home loan applications.
- Include external data, like current mortgage rates or housing market trends, to see how these factors influence loan applications.
By using algorithms and machine learning, propensity models can forecast future customer behavior. This helps in understanding not just what a customer has done, but what they are likely to do under certain circumstances.
Leverage Archive Data for Retrospective Analysis

Archive Data for Retrospective Analysis
The FinTech industry is quite different and more complex than the other tech spaces that we see in general, and particularly if we talk about the credit space, it demands a lot of trust and each action of yours needs justification. Hence, when we are talking about marketing in the credit space, having your archival or past data for retrospective analysis is a powerful approach to enhance data-driven marketing.
At this stage, it helps companies like yourselves to build on past successes, learn from failures, and continuously refine the marketing strategies based on solid, empirical evidence. At CodeDesign, we put a great emphasis on this step, as it not only allows us to make informed and better decisions, but also helps in anticipating customer needs, optimizing resource allocation, and staying agile in a dynamic market environment. For our client Eloan, we were very successful in understanding what their customers really resonated with only when we had a deep analysis of their archive data.
Here is our step by step tried and tested strategy that helped us improve their conversion rate for us:
Our first step was to look and analyze the historical data related to marketing campaigns, customer interactions, financial transactions, and more. For your startup, this could be data on previous loan offers, credit card promotions, customer responses, and engagement metrics. We are stressing about this historical data because this would help you understand what worked and what didn’t in past campaigns, providing valuable lessons for future strategies.
Which technique do we use for Retrospective Analysis?
We have a dedicated team of data professionals who employ advanced analytics techniques to extract patterns and trends from historical data.
Then the next step is Segmentation Analysis which involves looking at how different customer segments responded to past campaigns, which can reveal preferences and behaviors of specific groups.
The most important step that we always recommend is to compare the A/B Testing Results. Only when you review the outcomes from past A/B tests to understand what variations in campaigns led to better engagement or conversion rates, will you have a better understanding of what messaging or pain points actually resonate with your customers. See, in your campaign there should be no room for guesswork. It is all about how much data can back your claims.
Group your campaigns into various levels
When you identify which campaigns were most successful and why, you get to refine your overall messaging and branding aspect, because now you know how much your guesses actually stand in the actual market. Also, analyze the failures to understand what to avoid or improve.
There is nothing more important than incorporating feedback received during previous campaigns to refine messaging and offers. See, making strategies based on what pain points you are covering for your audience makes sense only when you have an actual mechanism to work on every single feedback by your customers.
Keep your focus on data quality for data-driven marketing

data quality for data driven marketing
See, in every step of data-driven marketing, prioritizing data quality is way more important than data quantity. Especially when we talk about your sector of FinTech, data is the cornerstone for making informed decisions, from credit risk assessment to personalized marketing strategies.
Thus, look to collect data from a variety of sources to avoid biases. This includes internal data (like transaction histories) and external data (like market trends). The next step that you have to keep in mind is ensuring accuracy and integrity from the point of data entry. For instance, using validation rules in data input forms (like correct formats for dates, non-negative values for certain numerical entries).
Also, one thing that we always recommend to our clients and partners in the FinTech space is to use a centralized system for data storage and management to ensure consistency and ease of access. And when you are trying to combine data from different sources, ensure it is integrated effectively, maintaining the context and relevance of data.
- Gather data from a wide array of sources including transaction histories, customer interactions, social media, and more, to create a holistic view of the customer.
- Ensure the data set is not biased towards a particular demographic. A diverse data set helps in making more accurate and universally applicable predictions.
- Regular checks for consistency and logical integrity of data (e.g., no negative values in age or income fields).
- Cross-referencing data with reliable sources to confirm its accuracy.
- Financial behaviors and patterns can change rapidly. Regular updates to the database are crucial to maintain its relevance and usefulness.
- Keeping track of macroeconomic trends and market shifts that could influence financial behaviors.
Do you have dedicated truth files for your marketing campaigns?
If you are wondering what Truth Files are then they are basically databases of known, verified, and accurate data that can be used as a benchmark. By comparing new or existing data against these truth files, companies can validate the accuracy of their data sets.
Few challenges and Solutions in Data Quality Management that we often recommend to our clients:
- As the volume of data increases, maintaining quality becomes more challenging. Implementing automated tools for data cleansing and validation can help.
- A lot of financial data is unstructured (like text from customer feedback). Using advanced data processing techniques like natural language processing can help in extracting meaningful information.
- Adhering to regulations like GDPR or CCPA is crucial in data handling, especially in the sensitive area of financial data.
- Implementing strong data security measures and respecting customer privacy is not just a legal requirement but also critical for customer trust.
FAQS - Frequently Asked Questions
What are propensity models and how do they benefit fintech marketing strategies?
Propensity models are sophisticated statistical tools that predict the likelihood of certain behaviors or actions by potential or existing customers, such as the probability of a customer purchasing a product, churning, or responding to a specific marketing campaign. In the context of fintech marketing strategies, these models offer a powerful advantage by enabling companies to identify and target segments of their audience that are most likely to engage with their products or services. By leveraging data-driven insights, fintech firms can tailor their marketing efforts to be more personalized and effective, significantly improving conversion rates and customer retention. For instance, Codedesign, a renowned digital marketing agency, has successfully implemented propensity models for its fintech clients, resulting in enhanced targeting precision and higher ROI on marketing investments. Through predictive analytics, these models analyze past customer behavior and various demographic and psychographic factors to forecast future actions, allowing marketers to allocate resources more efficiently and create highly relevant content and offers that resonate with their target audience.
How can fintech companies ensure the accuracy of their predictive models?
Ensuring the accuracy of predictive models in fintech requires a multifaceted approach focused on data quality, model validation, and continuous monitoring. First and foremost, fintech companies should invest in acquiring high-quality, relevant data, as the accuracy of any predictive model is directly tied to the quality of the input data. This involves cleaning, preprocessing, and ensuring the data is up-to-date and representative of the customer base. Secondly, rigorous validation techniques such as cross-validation should be employed to test the model's performance on unseen data, helping to avoid overfitting and underfitting. Additionally, incorporating a variety of models and comparing their performance can lead to more reliable predictions. Regularly updating the models to reflect new data and market conditions is also crucial. For instance, Codedesign often adopts an iterative approach to model development for its clients, incorporating feedback loops that allow continuous refinement and adjustment of models based on real-world performance. By adhering to these practices, fintech companies can significantly enhance the reliability and accuracy of their predictive analytics efforts.
What are the steps involved in building an effective model for predictive analysis in fintech?
Building an effective model for predictive analysis in fintech involves several critical steps designed to ensure the model's relevance, accuracy, and operational efficiency. Initially, it starts with defining the specific business problem or objective, such as predicting loan default rates or identifying high-value customers. Following this, data collection and preparation take center stage, where relevant data is gathered, cleaned, and preprocessed to ensure it's suitable for analysis. Feature selection and engineering are then conducted to identify the most predictive variables and potentially create new features that enhance the model's predictive power.
Subsequent to feature engineering, model selection is performed by choosing the appropriate statistical or machine learning algorithms that best fit the problem at hand. Algorithms such as logistic regression, decision trees, and neural networks are commonly considered based on the complexity of the problem and the nature of the data. The next step involves training the model on a subset of the data and validating its performance using another set, often through techniques like cross-validation, to ensure it generalizes well to unseen data.
Finally, the model is deployed in a live environment where it's continuously monitored and updated with new data to maintain its accuracy over time. Regular evaluation against key performance indicators (KPIs) ensures that the model remains aligned with business objectives. For example, Codedesign has leveraged this structured approach to build predictive models that have significantly improved marketing outcomes for its fintech clients, demonstrating the practical application and value of a methodical process in predictive analytics.
How can logistic regression, decision trees, and neural networks be applied in fintech marketing?
Logistic regression, decision trees, and neural networks can be applied in fintech marketing to drive personalized and effective marketing strategies through predictive analytics. Logistic regression, with its ability to estimate probabilities, is particularly useful for binary outcomes, such as predicting whether a customer will subscribe to a new service or not. This method can help fintech companies in segmenting their market and tailoring their communications for higher engagement rates.
Decision trees, on the other hand, are valuable for their interpretability and ease of use, making them ideal for identifying significant customer segments and the key variables that influence their behavior. This can inform targeted marketing campaigns and product development strategies that resonate with specific customer needs and preferences.
Neural networks, with their deep learning capabilities, are adept at handling complex patterns and interactions in large datasets. In fintech marketing, they can be used for sophisticated tasks like predicting customer lifetime value or personalizing product recommendations at scale. This allows for highly nuanced and effective targeting, enhancing customer satisfaction and loyalty.
Codedesign has effectively utilized these algorithms to optimize marketing strategies for fintech clients, achieving remarkable success in customer acquisition and retention by leveraging the predictive power of these models to deliver highly targeted and relevant marketing messages.
What is the process for training and testing models to predict customer behavior in the credit space?
The process for training and testing models to predict customer behavior in the credit space involves several key steps, aimed at creating accurate and reliable predictive models. Initially, it starts with data collection, where historical data on customer behavior, credit transactions, payment history, and other relevant information is gathered. This data is then preprocessed to handle missing values, outliers, and to ensure it's in a format suitable for analysis.
Feature selection and engineering follow, where variables that are most indicative of customer behavior in the credit space are identified and sometimes new features are created to improve the model's predictive capabilities. After selecting the appropriate features, the dataset is divided into a training set and a testing set, typically in a 70:30 or 80:20 ratio, to ensure the model can be trained on one subset of the data and tested on an independent subset to evaluate its performance.
Model training involves selecting an algorithm, such as logistic regression for binary outcomes or neural networks for more complex patterns, and using the training dataset to fit the model. This phase focuses on adjusting the model parameters to minimize prediction errors on the training data.
Testing the model is a critical step where the trained model is applied to the testing dataset to predict customer behavior. The model's performance is evaluated using metrics like accuracy, precision, recall, or the area under the receiver operating characteristic (ROC) curve, depending on the specific objectives of the model. This step is essential for assessing how well the model generalizes to new, unseen data.
Finally, continuous monitoring and updating of the model with new data are necessary to maintain its predictive accuracy over time. Regularly revisiting the model to adjust for changes in customer behavior or market conditions ensures that the predictive model remains relevant and effective. This process is crucial for fintech companies looking to leverage predictive analytics for credit risk assessment, customer segmentation, and personalized marketing strategies, as demonstrated by Codedesign's successful application of these models for its clients in the financial sector.
Why is leveraging archival data important for retrospective analysis in fintech marketing?
Leveraging archival data for retrospective analysis in fintech marketing is crucial for understanding past behaviors, trends, and outcomes, which can inform future strategies and decisions. This historical data provides a wealth of information that can help identify patterns in customer behavior, market movements, and the effectiveness of past marketing campaigns. By analyzing this data, fintech companies can uncover insights into what strategies worked well, which ones did not, and why certain outcomes occurred. This retrospective analysis is invaluable for refining targeting approaches, optimizing product offerings, and enhancing customer engagement strategies.
Furthermore, archival data can help in benchmarking performance over time, setting realistic targets based on historical trends, and forecasting future market behaviors. It also plays a critical role in risk management by enabling the analysis of past credit events or market downturns, helping companies to better prepare for potential future risks.
Codedesign, for example, has effectively utilized archival data to conduct retrospective analyses for its fintech clients, leading to improved marketing strategies that are informed by historical performance and market trends. By leveraging this data, fintech companies can make more informed decisions, allocate their marketing resources more effectively, and ultimately achieve a competitive edge in the market.
How can fintech companies improve their marketing strategies based on historical data analysis?
Fintech companies can significantly enhance their marketing strategies based on historical data analysis by employing several key approaches. First, by segmenting their customer base using historical behavior and transaction data, companies can identify distinct customer segments with similar needs or behaviors. This segmentation allows for more personalized and effective marketing campaigns tailored to the specific preferences and needs of different groups.
Second, historical data analysis can reveal the effectiveness of previous marketing campaigns, including which channels, messages, and offers yielded the highest engagement and conversion rates. By identifying these successful elements, fintech companies can optimize future campaigns to replicate and build on past successes.
Third, trend analysis over time can help fintech companies understand how customer behaviors and preferences are evolving. This insight is crucial for developing forward-looking strategies that anticipate and meet emerging customer needs, keeping the company ahead of market trends.
Moreover, predictive analytics can be applied to historical data to forecast future behaviors, such as the likelihood of customer churn, potential high-value customers, or the response to new products or services. This foresight enables fintech companies to proactively address customer needs, optimize product offerings, and tailor marketing messages to improve engagement and retention.
Codedesign has effectively guided its fintech clients in utilizing historical data analysis to refine their marketing strategies, leading to enhanced customer engagement, higher conversion rates, and improved overall marketing efficiency. By systematically analyzing historical data, fintech companies can make data-driven decisions that significantly improve their marketing outcomes.
What techniques are recommended for conducting a thorough retrospective analysis?
For conducting a thorough retrospective analysis, several recommended techniques can be employed to extract meaningful insights from historical data. Time-series analysis is crucial for understanding trends over time, such as changes in customer behavior, market conditions, or the performance of marketing campaigns. This technique allows companies to identify patterns, seasonality, and potential causality in their data.
Cohort analysis is another valuable technique, segmenting customers into cohorts based on shared characteristics or behaviors over a specific time period. This approach helps in understanding how different customer groups behave and evolve over time, providing insights into customer lifecycle, retention rates, and the long-term value of different segments.
Comparative analysis is also important, comparing the performance of different marketing strategies, channels, or customer segments against each other. This can help identify the most and least effective strategies and inform future marketing decisions.
Moreover, regression analysis can be used to identify relationships between different variables and their impact on key outcomes, such as sales, customer engagement, or churn rates. This helps in understanding the factors that drive success and can guide strategic adjustments.
Finally, machine learning models can be applied for more sophisticated analyses, such as predicting future trends based on historical data or identifying hidden patterns that might not be apparent through traditional analysis methods.
By employing these techniques, companies like Codedesign have been able to conduct in-depth retrospective analyses for their fintech clients, uncovering valuable insights that have informed more effective marketing strategies and business decisions.
How does focusing on data quality impact data-driven marketing effectiveness in the fintech industry?
Focusing on data quality has a profound impact on the effectiveness of data-driven marketing in the fintech industry. High-quality data is fundamental for accurate analysis, reliable predictions, and effective decision-making. When data is accurate, complete, consistent, and timely, it provides a solid foundation for understanding customer behavior, preferences, and needs.
Quality data enables more precise segmentation, targeting, and personalization of marketing efforts, leading to higher engagement rates and conversion. It ensures that marketing messages are relevant and resonate with the intended audience, enhancing customer experience and satisfaction. Moreover, clean and reliable data reduces the risk of making incorrect decisions based on faulty or misleading information, which can lead to wasted resources and missed opportunities.
For predictive models and analytics to be effective, they require high-quality input data. Poor data quality can lead to inaccurate predictions, misdirected marketing strategies, and an inability to identify true market opportunities or risks. Fintech companies that prioritize data quality can better identify trends, predict customer behavior, and optimize their marketing strategies for maximum impact.
Codedesign, through its work with fintech clients, has demonstrated the importance of maintaining high data quality standards. By ensuring the accuracy and reliability of their data, these companies have been able to leverage data-driven insights to drive growth, improve customer retention, and achieve a competitive advantage in the market.
What are some common challenges in data quality management for fintech, and how can they be addressed?
Common challenges in data quality management for fintech include data inconsistency, incompleteness, and the rapid obsolescence of data due to the fast-paced nature of the financial industry. Inconsistencies may arise from disparate data sources, leading to conflicts and inaccuracies. Incompleteness refers to missing data elements that are crucial for analysis and decision-making. Rapid obsolescence reflects the challenge of keeping data relevant in an industry where customer preferences, financial products, and regulatory environments can change quickly.
To address these challenges, fintech companies can implement robust data governance frameworks that establish clear policies and procedures for data management, including quality standards, data collection methods, and regular audits to ensure compliance. Automated data cleaning and validation tools can be employed to identify and correct data inconsistencies and gaps, improving the accuracy and reliability of the data.
Data integration platforms can help in consolidating data from various sources, ensuring consistency and reducing duplication. Implementing a centralized data management system can also enhance accessibility and reliability of data across the organization.
Furthermore, adopting advanced analytics and machine learning techniques can aid in identifying and correcting data quality issues, as well as in adapting to changes in data patterns over time. Continuous monitoring and updating of data practices are essential to keep pace with the evolving fintech landscape.
Codedesign has supported its fintech clients in overcoming these data quality challenges by advising on best practices for data management and leveraging technology solutions that ensure the integrity and reliability of their data. By addressing these challenges effectively, fintech companies can enhance the quality of their data-driven marketing efforts, leading to better customer insights, improved decision-making, and competitive advantage.

Add comment ×